 Project ENCODE (ENCyclopedia of DNA Elements) results were recently announced. The ENCODE project was done by a consortium of over 400 researchers from 32 institutions and has deciphered the functionality of so called Junk DNA in the human genome. They have determined that junk DNA is actually used to regulate gene expression. Or junk DNA is really on-off switches for protein encoding DNA. ENCODE project results were published by Nature, Scientific American, New York Times and others.
Project ENCODE (ENCyclopedia of DNA Elements) results were recently announced. The ENCODE project was done by a consortium of over 400 researchers from 32 institutions and has deciphered the functionality of so called Junk DNA in the human genome. They have determined that junk DNA is actually used to regulate gene expression. Or junk DNA is really on-off switches for protein encoding DNA. ENCODE project results were published by Nature, Scientific American, New York Times and others.
The paper in Nature ENCODE Explained is probably the best introduction to the project. But probably the best resource on the project computational aspects comes from these papers at Nature, The making of ENCODE lessons for BIG data projects by Ewan Birney and ENCODE: the human encyclopedia by Brendan Maher.
I have been following the Bioinformatics/DNA scene for some time now. (Please see Genome Informatics …, DITS, Codons, & Chromozones …, DNA Computing …, DNA Computing … – part 2). But this is perhaps the first time it has all come together to explain the architecture of DNA and potentially how it all works together to define a human.
Project ENCODE results
It seems like there were at least four major results from the project.
- Junk DNA is actually programming for protein production in a cell. Scientists previously estimated that <3% of human DNA’s over 3 billion base pairs encode for proteins. Recent ENCODE results seem to indicate that at least 9% of this human DNA and potentially, as much as 50% provide regulation for when to use those protein encoding DNA.
- Regulation DNA undergoes a lot of evolutionary drift. That is it seems to be heavily modified across species. For instance, protein encoding genes seem to be fairly static and differ very little between species. On the the other hand, regulating DNA varies widely between these very same species. One downside to all this evolutionary variation is that regulatory DNA also seems to be the location for many inherited diseases.
- Project ENCODE has further narrowed the “Known Unknowns” of human DNA. For instance, about 80% of human DNA is transcribed by RNA. Which means on top of the <3% protein encoding DNA and ~9-50% regulation DNA already identified, there is another 68 to 27% of DNA that do something important to help cells transform DNA into life giving proteins. What that residual DNA does is TBD and is subject for the next phase of the ENCODE project (see below).
- There are cell specific regulation DNA. That is there are regulation DNA that are specifically activated if it’s bone cell, skin cell, liver cell, etc. Such cell specific regulatory DNA helps to generate the cells necessary to create each of our organs and regulate their functions. I suppose this was a foregone conclusion but it’s proven now
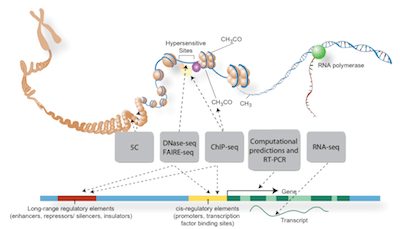
There are promoter regulatory DNA which are located ahead and in close proximity to the proteins that are being encoded and enhancer/inhibitor regulatory DNA which are located a far DNA distance away from the proteins they regulate.
I believe it seems that we are seeing two different evolutionary time frames being represented in the promoter vs. enhancer/inhibitor regulatory DNA. Whereas promoter DNA seem closely associated with protein encoding DNA, the enhancer DNA seems more like patches or hacks that fixed problems in the original promoter-protein encoding DNA sequences, sort of like patch Tuesday DNA that fixes problems with the original regulation activity.
While I am excited about Project ENCODE results. I find the big science/big data aspects somewhat more interesting.
Genome Big Science/Big Data at work
Some stats from the ENCODE Project:
- Almost 1650 experiments on around 180 cell types were conducted to generate data for the ENCODE project. All told almost 12,000 files were analyzed from these experiments.
- 15TB of data were used in the project
- ENCODE project internal Wiki had 18.5K page edits and almost 250K page views.
With this much work going on around the world, data quality control was a necessary, ongoing consideration. It took about half way into the project before they figured out how to define and assess data quality from experiments. What emerged from this was a set of published data standards (see data quality UCSC website) used to determine if experimental data were to be accepted or rejected as input to the project. In the end the retrospectively applied the data quality standards to the earlier experiments and had to jettison some that were scientifically important but exhibited low data quality.
There was a separation between the data generation team (experimenters) and the data analysis team. The data quality guidelines represented a key criteria that governed these two team interactions.
Apparently the real analysis began when they started layering the base level experiments on top of one another. This layering activity led to researchers further identifying the interactions and associations between regulatory DNA and protein encoding DNA.
All the data from the ENCODE project has been released and are available to anyone interested. They also have provided a search and browser capability for the data. All this can be found on the top UCSC website. Further, from this same site one can download the software tools used to analyze, browse and search the data if necessary.
This multi-year project had an interesting management team that created a “spine of leadership”. This team consisted of a few leading scientists and a few full time scientifically aware project officers that held the project together, pushed it along and over time delivered the results.
There were also a set of elaborate rules that were crafted so that all the institutions, researchers and management could interact without friction. This included rules guiding data quality (discussed above), codes of conduct, data release process, etc.
What no Hadoop?
What I didn’t find was any details on the backend server, network or storage used by the project or the generic data analysis tools. I suspect Hadoop, MapReduce, HBase, etc. were somehow involved but could find no reference to this.
I expected with the different experiments and wide variety of data fusion going on that there would be some MapReduce scripting that would transcribe the data so it could be further analyzed by other project tools. Alas, I didn’t find any information about these tools in the 30+ research papers that were published in the last week or so.
It looks like the genomic analysis tools used in the ENCODE project are all open source. They useh the OpenHelix project deliverables. But even a search of the project didn’t reveal any hadoop references.
~~~~
The ENCODE pilot project (2003-2007) cost ~$53M, the full ENCODE project’s recent results cost somewhere around $130M and they are now looking to the next stage of the ENCODE project estimated to cost ~$123M. Of course there are 1000s of more human cell types that need to be examined and ~30% more DNA that needs to be figured out. But this all seems relatively straight forward now that the ENCODE project has laid out an architectural framework for human DNA.
Anyone out there that knows more about the data processing/data analytics side of the ENCODE project please drop me a line. I would love to hear more about it or you can always comment here.
Comments?
Image: From Project Encode, Credits: Darryl Leja (NHGRI), Ian Dunham (EBI)

")
")
 (from flickr)")