
 Read a couple of articles this week Inching closer to a DNA-based file system in ArsTechnica and DNA storage gets random access in IEEE Spectrum. Both of these seem to be citing an article in Nature, Random access in large-scale DNA storage (paywall).
Read a couple of articles this week Inching closer to a DNA-based file system in ArsTechnica and DNA storage gets random access in IEEE Spectrum. Both of these seem to be citing an article in Nature, Random access in large-scale DNA storage (paywall).
We’ve known for some time now that we can encode data into DNA strings (see my DNA as storage … and Genomic informatics takes off posts).
However, accessing DNA data has been sequential and reading and writing DNA data has been glacial. Researchers have started to attack the sequentiality of DNA data access. The prize, DNA can store 215PB of data in one gram and DNA data can conceivably last millions of years.
 Researchers at Microsoft and the University of Washington have come up with a solution to the sequential access limitation. They have used polymerase chain reaction (PCR) primers as a unique identifier for files. They can construct a complementary PCR primer that can be used to extract just DNA segments that match this primer and amplify (replicate) all DNA sequences matching this primer tag that exist in the cell.
Researchers at Microsoft and the University of Washington have come up with a solution to the sequential access limitation. They have used polymerase chain reaction (PCR) primers as a unique identifier for files. They can construct a complementary PCR primer that can be used to extract just DNA segments that match this primer and amplify (replicate) all DNA sequences matching this primer tag that exist in the cell.
DNA data format
The researchers used a Reed-Solomon (R-S) erasure coding mechanism for data protection and encode the DNA data into many DNA strings, each with multiple (metadata) tags on them. One of tags is the PCR primer tag header, another tag indicates the position of the DNA data segment in the file and an end of data tag that is the same PCR primer tag.
The PCR primer tag was used as sort of a file address. They could configure a complementary PCR tag to match the primer tag of the file they wanted to access and then use the PCR process to replicate (amplify) only those DNA segments that matched the searched for primer tag.
 Apparently the researchers chunk file data into a block of 150 base pairs. As there are 2 complementary base pairs, I assume one bit to one base pair mapping. As such, 150 base pairs or bits of data per segment means ~18 bytes of data per segment. Presumably this is to allow for more efficient/effective encoding of data into DNA strings.
Apparently the researchers chunk file data into a block of 150 base pairs. As there are 2 complementary base pairs, I assume one bit to one base pair mapping. As such, 150 base pairs or bits of data per segment means ~18 bytes of data per segment. Presumably this is to allow for more efficient/effective encoding of data into DNA strings.
DNA strings don’t work well with replicated sequences of base pairs, such as all zeros. So the researchers created a random sequence of 150 base pairs and XOR the file DNA data with this random sequence to determine the actual DNA sequence to use to encode the data. Reading the DNA data back they need to XOR the data segment with the random string again to reconstruct the actual file data segment.
Not clear how PCR replicated DNA segments are isolated and where they are originally decoded (with a read head). But presumably once you have thousands to millions of copies of a DNA segment, it’s pretty straightforward to decode them.
Once decoded and XORed, they use the R-S erasure coding scheme to ensure that the all the DNA data segments represent the actual data that was encoded in them. They can then use the position of the DNA data segment tag to indicate how to put the file data back together again.
What’s missing?
I am assuming the cellular data storage system has multiple distinct cells of data, which are clustered together into some sort of organism.
Each cell in the cellular data storage system would hold unique file data and could be extracted and a file read out individually from the cell and then the cell could be placed back in the organism. Cells of data could be replicated within an organism or to other organisms.
To be a true storage system, I would think we need to add:
- DNA data parity – inside each DNA data segment, every eighth base pair would be a parity for the eight preceding base pairs, used to indicate when a particular base pair in eight has mutated.
- DNA data segment (block) and file checksums – standard data checksums, used to verify and correct for double and triple base pair (bit) corruption in DNA data segments and in the whole file.
- Cell directory – used to indicate the unique Cell ID of the cell, a file [name] to PCR primer tag mapping table, a version of DNA file metadata tags, a version of the DNA file XOR string, a DNA file data R-S version/level, the DNA file length or number of DNA data segments, the DNA data creation data time stamp, the DNA last access date-time stamp,and DNA data modification data-time stamp (these last two could be omited)
- Organism directory – used to indicate unique organism ID, organism metadata version number, organism unique cell count, unique cell ID to file list mapping, cell ID creation data-time stamp and cell ID replication count.
The problem with an organism cell-ID file list is that this could be quite long. It might be better to somehow indicate a range or list of ranges of PCR primer tags that are in the cell-ID. I can see other alternatives using a segmented organism directory or indirect organism cell to file lists b-tree, which could hold file name lists to cell-ID mapping.
 It’s unclear whether DNA data storage should support a multi-level hierarchy, like file system directories structures or a flat hierarchy like object storage data, which just has buckets of objects data. Considering the cellular structure of DNA data it appears to me more like buckets and the glacial access seems to be more useful to archive systems. So I would lean to a flat hierarchy and an object storage structure.
It’s unclear whether DNA data storage should support a multi-level hierarchy, like file system directories structures or a flat hierarchy like object storage data, which just has buckets of objects data. Considering the cellular structure of DNA data it appears to me more like buckets and the glacial access seems to be more useful to archive systems. So I would lean to a flat hierarchy and an object storage structure.
Is DNA data is WORM or modifiable? Given the effort required to encode and create DNA data segment storage, it would seem it’s more WORM like than modifiable storage.
How will the DNA data storage system persist or be kept alive, if that’s the right word for it. There must be some standard internal cell mechanisms to maintain its existence. Perhaps, the researchers have just inserted file data DNA into a standard cell as sort of junk DNA.
 If this were the case, you’d almost want to create a separate, data nucleus inside a cell, that would just hold file data and wouldn’t interfere with normal cellular operations.
If this were the case, you’d almost want to create a separate, data nucleus inside a cell, that would just hold file data and wouldn’t interfere with normal cellular operations.
But doesn’t the PCR primer tag approach lend itself better to a key-value store data base?
Photo Credit(s): Cell structure National Cancer Institute
Guide to Open VMS file applications
Unix Inodes CSE410 Washington.edu
Key Value Databases, Wikipedia By Clescop – Own work, CC BY-SA 4.0, Link

 There’s been a lot of talk on the extendability of current AI this past week and it appears that while we may have a good deal of runway left on the machine learning/deep learning/pattern recognition, there’s something ahead that we don’t understand.
There’s been a lot of talk on the extendability of current AI this past week and it appears that while we may have a good deal of runway left on the machine learning/deep learning/pattern recognition, there’s something ahead that we don’t understand. Where’s HAL?
Where’s HAL? There’s a case to be made that all mammalian intelligence is based on hierarchies of pattern recognition capabilities.
There’s a case to be made that all mammalian intelligence is based on hierarchies of pattern recognition capabilities. Most babies understand their parents language(s) and learn to crawl within months after birth. But they haven’t listened to thousands of hours of people talking or crawled thousands of miles. And yet, deep learning requires even more learning sets in order to label language properly or learning how to crawl on four appendages. And of course, understanding language and speaking it are two different capabilities. Ditto for crawling and walking.
Most babies understand their parents language(s) and learn to crawl within months after birth. But they haven’t listened to thousands of hours of people talking or crawled thousands of miles. And yet, deep learning requires even more learning sets in order to label language properly or learning how to crawl on four appendages. And of course, understanding language and speaking it are two different capabilities. Ditto for crawling and walking.
 Read an article the other week from Scientific American on
Read an article the other week from Scientific American on  Geologist and geomorphologists from Washington State and the USGS have been instrumenting Rattlesnake Ridge with over 70 GPS sensors. They are also following the landslide using LIDAR snapshots to map terrain movement to try to better understand that movement over time.
Geologist and geomorphologists from Washington State and the USGS have been instrumenting Rattlesnake Ridge with over 70 GPS sensors. They are also following the landslide using LIDAR snapshots to map terrain movement to try to better understand that movement over time. There’s a website called
There’s a website called 
 Read an article today in Bitcoin magazine
Read an article today in Bitcoin magazine  Blockchain data is inherently widely available and distributed, in fact, blockchain data needs to be widely distributed in order to work properly.
Blockchain data is inherently widely available and distributed, in fact, blockchain data needs to be widely distributed in order to work properly. The ixo Protocol is a method to manage (SDG) Impact projects. It starts with 3 main participants: funding agencies, service agents and evaluation agents.
The ixo Protocol is a method to manage (SDG) Impact projects. It starts with 3 main participants: funding agencies, service agents and evaluation agents.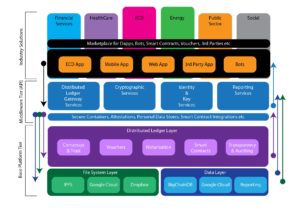 The
The 
 Jansen had told Sauder’s team that his devices work much better on smooth surfaces and that uneven, beach like surfaces presented problems.
Jansen had told Sauder’s team that his devices work much better on smooth surfaces and that uneven, beach like surfaces presented problems. They’re not planning to ditch electronics all together but need to minimize the rovers reliance on electronics.
They’re not planning to ditch electronics all together but need to minimize the rovers reliance on electronics. In order to avoid obstacles wihile roving around the planet, they plan to use a mechanical probe out othe front (and back?) of the rover with control systems attached to this to avoid obstacles. This way the rover can move around more of the planets surface.
In order to avoid obstacles wihile roving around the planet, they plan to use a mechanical probe out othe front (and back?) of the rover with control systems attached to this to avoid obstacles. This way the rover can move around more of the planets surface. Radio works but why not use infrared. If there were some way to read an infrared signal from the probe, it could present more information per pass.
Radio works but why not use infrared. If there were some way to read an infrared signal from the probe, it could present more information per pass. What about steam power. With 450C there ought to be more than enough heat to boil some liquid and have it cool via expansion. Having cool liquid could be used to cool electronics, chemical and solar devices. And as the high temperatures on Venus seem constant, steam power and liquid cooling would be available all the time and eliminating any need for springs to hold energy.
What about steam power. With 450C there ought to be more than enough heat to boil some liquid and have it cool via expansion. Having cool liquid could be used to cool electronics, chemical and solar devices. And as the high temperatures on Venus seem constant, steam power and liquid cooling would be available all the time and eliminating any need for springs to hold energy. Still not sure why we need any electronics. A suitably configured, shrunken, analytical engine could provide the rudimentary information processing necessary to work the shutter or other transmitter mechanisms, initiate, readout and store mechanical/chemical/sonar sensors and control the other items on the rover.
Still not sure why we need any electronics. A suitably configured, shrunken, analytical engine could provide the rudimentary information processing necessary to work the shutter or other transmitter mechanisms, initiate, readout and store mechanical/chemical/sonar sensors and control the other items on the rover. And with a suitably complex analytical engine there might be some way to mechanically program it with various modes using something like punched tape or cards. Such a device could be used to hold and load information for separate programs in minimal space and could also be used to store information for later transmission, supplying a 100% mechanical storage device.
And with a suitably complex analytical engine there might be some way to mechanically program it with various modes using something like punched tape or cards. Such a device could be used to hold and load information for separate programs in minimal space and could also be used to store information for later transmission, supplying a 100% mechanical storage device.
 Last week WDC announced their next generation technology for hard drives, MAMR or Microwave Assisted Magnetic Recording. This is in contrast to HAMR, Heat (laser) Assisted Magnetic Recording. Both techniques add energy so that data can be written as smaller bits on a track.
Last week WDC announced their next generation technology for hard drives, MAMR or Microwave Assisted Magnetic Recording. This is in contrast to HAMR, Heat (laser) Assisted Magnetic Recording. Both techniques add energy so that data can be written as smaller bits on a track. The problem with PMR-SMR-TDMR is that the max achievable disk density is starting to flat line and approaching the “WriteAbility limit” of the head-media combination.
The problem with PMR-SMR-TDMR is that the max achievable disk density is starting to flat line and approaching the “WriteAbility limit” of the head-media combination.
 It turns out that HAMR as it uses heat to add energy, heats the media drives to much higher temperatures than what’s normal for a disk drive, something like 400C-700C. Normal operating temperatures for disk drives is ~50C. HAMR heat levels will play havoc with drive reliability. The view from WDC is that HAMR has 100X worse reliability than MAMR.
It turns out that HAMR as it uses heat to add energy, heats the media drives to much higher temperatures than what’s normal for a disk drive, something like 400C-700C. Normal operating temperatures for disk drives is ~50C. HAMR heat levels will play havoc with drive reliability. The view from WDC is that HAMR has 100X worse reliability than MAMR. In order to generate that much heat, HAMR needs a laser to expose the area to be written. Of course the laser has to be in the head to be effective. Having to add a laser and optics will increase the cost of the head, increase the steps to manufacture the head, and require new suppliers/sourcing organizations to supply the componentry.
In order to generate that much heat, HAMR needs a laser to expose the area to be written. Of course the laser has to be in the head to be effective. Having to add a laser and optics will increase the cost of the head, increase the steps to manufacture the head, and require new suppliers/sourcing organizations to supply the componentry. MAMR uses microwaves to add energy to the spot being recorded. The microwaves are generated by a Spin Torque Oscilator, (STO), which is a solid state device, compatible with CMOS fabrication techniques. This means that the MAMR head assembly (PMR & STO) can be fabricated on current head lines and within current head mechanisms.
MAMR uses microwaves to add energy to the spot being recorded. The microwaves are generated by a Spin Torque Oscilator, (STO), which is a solid state device, compatible with CMOS fabrication techniques. This means that the MAMR head assembly (PMR & STO) can be fabricated on current head lines and within current head mechanisms. WDC believes that by 2020, ~90% of enterprise data will be stored on hard drives. However, this is predicated on achieving a continuing, 10X cost differential between disk drives and (QLC 3D) flash.
WDC believes that by 2020, ~90% of enterprise data will be stored on hard drives. However, this is predicated on achieving a continuing, 10X cost differential between disk drives and (QLC 3D) flash.
 I have not reported on new battery structures or materials in the past but it seems that every week or so I run across another article or two on the latest battery technology that will change everything. Yet this one just might do that.
I have not reported on new battery structures or materials in the past but it seems that every week or so I run across another article or two on the latest battery technology that will change everything. Yet this one just might do that. Moore’s law will eventually cease. It’s only a question of time and materials.
Moore’s law will eventually cease. It’s only a question of time and materials. But just maybe the endgame in chip fabrication materials and possibly many other domains seems to be new materials coming out of ETH Zurich Switzerland.
But just maybe the endgame in chip fabrication materials and possibly many other domains seems to be new materials coming out of ETH Zurich Switzerland. 
 Read an article the other day in MIT news, (
Read an article the other day in MIT news, ( The bottom layer is a silicon based CPU. On top of the silicon is a carbon nanotube layer. Next comes the RRAM and the top layer is more carbon nanotubes making up the sensor array.
The bottom layer is a silicon based CPU. On top of the silicon is a carbon nanotube layer. Next comes the RRAM and the top layer is more carbon nanotubes making up the sensor array. The chip as fabricated has a million RRAM cells (bits?) and 2 million nanotube FETs. In contrast, in 2014, Intel’s 15-core Xeon Ivy Bridge EX had 4.3B transistors and current DRAM chips offer 64Gb. So there’s a ways to go before carbon nanotube and RRAM densities can get to a level available from silicon today.
The chip as fabricated has a million RRAM cells (bits?) and 2 million nanotube FETs. In contrast, in 2014, Intel’s 15-core Xeon Ivy Bridge EX had 4.3B transistors and current DRAM chips offer 64Gb. So there’s a ways to go before carbon nanotube and RRAM densities can get to a level available from silicon today.{kind=link}
{kind=link}