
So as to my forecast for the first question of the week: (#Storage-QoW 2015-001) – Will 3D XPoint be GA’d in enterprise storage systems within 12 months?
I believe the answer will be Yes with a 0.38 probability or conversely, No with a 0.62 probability.
We need to decompose the question to come up with a reasonable answer.
1. How much of an advantage will 3D XPoint provide storage systems?
The claim is 1000X faster than NAND, 1000X endurance of NAND, & 10X density of DRAM. But, I believe the relative advantage of the new technology depends mostly on its price. So now the question is what would 3D XPoint technology cost ($/GB).
It’s probably going to be way more expensive than NAND $/GB (@2.44/64Gb-MLC or ~$0.31/GB). But how will it be priced relative to DRAM (@$2.23/4Gb DDR4 or ~$4.46/GB) and (asynch) SRAM (@$7.80/ 16Mb or $3900.00/GB)?
More than likely, it’s going to cost more than DRAM because it’s non-volatile and almost as fast to access. As for how it relates to SRAM, the pricing gulf between DRAM and asynch SRAM is so huge, I think pricing it even at 1/10th SRAM costs, would seriously reduce the market. And I don’t think its going to be too close to DRAM, so maybe ~10X the cost of DRAM, or $44.60/GB. [Probably more like a range of prices with $44.60 at 0.5 probable, $22.30 at 0.25 and $66.90 at 0.1. Unclear how I incorporate such pricing variability into a forecast.]
At $44.60/GB, what could 3D XPoint NVM replace in a storage system: 1) non-volatile cache; 2) DRAM caches, 3) Flash caches; 4) PCIe flash storage or 5) SSD storage in storage control units.
Non-volatile caching uses battery backed DRAM (with or without SSD offload) and SuperCap backed DRAM with SSD offload. Non-volatile caches can be anywhere from 1/16 to 1/2 total system cache size. The average enterprise class storage has ~412GB of cache, so non-volatile caching could be anywhere from 26 to 206GB or lets say ~150GB of 3D XPoint, which at ~$45/GB, would cost $6.8K in chips alone, add in $1K of circuitry and it’s $7.8K
- For battery backed DRAM – 150GB of DRAM would cost ~$670 in chips, plus an SSD (~300GB) at ~$90, and 2 batteries (8hr lithium battery costs $32) so $64. Add charging/discharging circuitry, battery FRU enclosures, (probably missing something else) but maybe all the extras come to another $500 or ~$1.3K total. So the at $45/GB the 3D Xpoint non-volatile cache would run ~6.0X the cost of battery backed up DRAM.
- For superCAP backed DRAM – similarly, a SuperCAP cache would have the same DRAM and SSD costs ($670 & $90 respectively). The costs for SuperCAPS in equivalent (Wh) configurations, run 20X the price of batteries, so $1.3K. Charging/discharging circuitry and FRU enclosures would be simpler than batteries, maybe 1/2 as much, so add $250 for all the extras, which means a total SuperCAP backed DRAM cost of ~$2.3K., which puts 3D Xpoint at 3.4X the cost of superCAP backed DRAM.
In these configurations a 3D XPoint non-volatile memory would replace lot’s of circuitry (battery-charging/discharging & other circuitry or SuperCAP-charging/discharging & other circuitry) and the SSD. So, 3D XPoint non-volatile cache could drastically simplify hardware logic and also software coding for power outages/failures. Less parts and coding has some intrinsic value beyond pure cost, difficult to quantify, but substantive, nonetheless.
As for using 3D XPoint to replace volatile DRAM cache another advantage is you wouldn’t need to have a non-volatile cache and systems wouldn’t have to copy data between caches. But at $45/GB, costs would be significant. A 412GB DRAM cache would cost $1.8K in DRAM chips and maybe another $1K in circuitry, so~ $2.8K. Doing one in 3D XPoint would run $18K in chips and the same $1K in circuitry, so $19K. But we eliminate the non-volatile cache. Factoring that in, the all 3D XPoint cache would run ~$19K vs. DRAM volatile and (SuperCAP backed) non-volatile cache $2.8K+$2.3K= $5.1 or ~3.7X higher costs.
Again, the parts cost differential is not the whole story. But replacing volatile cache AND non-volatile cache would probably require more coding not less.
As for using 3D XPoint as a replacement or FlashCache I don’t think it’s likely because the cost differential at $45/GB is ~100X Flash costs (not counting PCIe controller and other logic) . Ditto for PCIe Flash and SSD storage.
Being 1000X denser than DRAM is great, but board footprint is not a significant storage system cost factor today.
So at a $45/GB price maybe there’s a 0.35 likelihood that storage systems would adopt the technology.
2. How many vendors are likely to GA new enterprise storage hardware in the next 12 months?
We can use major vendors to help estimate this. I used IBM, EMC, HDS, HP and NetApp as representing the major vendors for this analysis.
IBM (2 for 4)
- They just released a new DS8880 last fall and their prior version DS8870 came out in Oct. 2013, so the DS8K seems to be on a 24 month development cycle. So, its very unlikely we will see a new DS8K be released in next 12 month.
- SVC engine hardware DH8 was introduced in May 2014. SVC CG8 engine was introduced in May 2011. So SVC hardware seems to be on a 36 month cycle. So, its very unlikely we will see a new SVC hardware engine will be released in the next 12 months.
- FlashSystem 900 hardware was just rolled out 1Q 2015 and FlashSystem 840 was introduced in January of 2014. So FlashSystem hardware is on a ~15 month hardware cycle. So, it is very likely that a new FlashSystem hardware will be released in the next 12 months.
- XIV Gen 3 hardware was introduced in July of 2011. Unclear when Gen2 was rolled out but IBM acquired XIV in Jan of 2008 and released an IBM version in August, 2008. So XIV’s on a ~36 month cycle. So, it is very likely that a new generation of XIV will be released in the next 12 months.
EMC ([4] 3 for 4)
- VMAX3 was GA’d in 3Q (Sep) 2014. VMAX2 was available Sep 2012, which puts VMAX on 24 month cycle. So, it’s very likely that a new VMAX will be released in the next 12 months.
- VNX2 was announced May, 2013 and GA’d Sep 2013. VNX 1 was announced Jan ,2011 and GA’d by May 2011. So that puts VNX on a ~28 month cycle. Which means we have should have already seen a new one, so it’s very likely we will see a new version of VNX in the next 12 months.
- XtremIO hardware was introduced in Mar, 2013 with no new significant hardware changes since. With a lack of history to guide us let’s assume a 24 month cycle. So, it’s very likely we will see a new version of XtremIO hardware in the next 12 months.
- Isilon S200/X200 was introduced April, 2011 and X400 was released in May, 2012. Which put Isilon on a 13 month cycle then but nothing since. So, it’s very likely we will see a new version of Isilon hardware in the next 12 months.
However, having EMC’s unlikely to update all their storage hardware in the same 12 moths. That being said, XtremIO could use a HW boost as IBM and the startups are pushing AFA technology pretty hard here. Isilon is getting long in the tooth, so that’s another likely changeover. Since VNX is more overdue than VMAX, I’d have to say it’s likely new VNX, XtremIO & Isilon hardware will be seen over the next year.
HDS (1 of 3)
- Hitachi VSP G1000 came out in Apr of 2014. HDS VSP came out in Sep of 2010. So HDS VSP is on a 43 month cycle. So it’s very unlikely we will see a new VSP in 12 months.
- Hitachi HUS VM came out in Sep 2012. As far as I can tell there were no prior generation systems. But HDS just came out with the G200-G800 series, leaving the HUS VM as the last one not updated so, it’s very likely we will see a new version of HUS VM in the next 12 months.
- Hitachi VSP G800, G600, G400, G200 series came out in Nov of 2015. Hitachi AMS 2500 series came out in April, 2012. So the mid-range systems seem to be on an 43 month cycle. So it’s very unlikely we will see a new version of HDS G200-G800 series in the next 12 months.
HP (1 of 2)
- HP 3PAR 20000 was introduced August, 2015 and the previous generation system, 3PAR 10000 was introduced in June, 2012. This puts the 3PAR on a 38 month cycle. So it’s very unlikely we will see a new version of 3PAR in the next 12 months.
- MSA 1040 was introduced in Mar 2014. MSA 2040 was introduced in May 2013. This puts the MSA on ~10 month cycle. So it’s very likely we will see a new version of MSA in the next 12 months.
NetApp (2 of 2)
- FAS8080 EX was introduced June, 2014. FAS6200 was introduced in Feb, 2013. Which puts the highend FAS systems on a 16 month cycle. So it’s very likely we will see a new version high-end FAS in the next 12 months.
- NetApp FAS8040-8060 series scale out systems were introduced in Feb 2014. FAS3200 series was introduced in Nov of 2012. Which puts the FAS systems on a 15 month cycle. A new midrange release seems overdue, so it’s very likely we will see a new version of mid-range FAS in the next 12 months.
Overall the likelihood of new hardware being released by major vendors is 2+3+1+1+2=9/15 or ~0.60 probability of new hardware in the next 12 months.
Applying 0.60 to non-major storage vendors that typically only have one storage system GA’d at a time, which includes Coho Data, DataCore, Data Gravity, Dell, DDN, Fujitsu, Infinidat, NEC, Nexenta, NexGen Storage, Nimble, Pure, Qumulo, Quantum, SolidFire, Tegile, Tintri, Violin Memory, X-IO, and am probably missing a couple more. So of these ~21 non-major/startup vendors, we are likely to see ~13 new (non-major) hardware systems in the next 12 months.
Some of these non-major systems are based on standard off-the-shelf, Intel server hardware and some vendors (Infinidat, Violin Memory & X-IO) have their own hardware designed systems. Of the 9 major vendor products identified above, six (IBM XIV, EMC VNX, EMC Isilon, EMC XtremIO, HP MSA and NetApp mid-range) use off the shelf, server hardware.
So all told my best guess is we should see (9+13=)22 new enterprise storage systems introduced in next 12 months from major and non-major storage vendors.
3. How likely is it that Intel-Micron will come out with GA chip products in the next 6 months?
They claimed they were sampling products to vendors back at Flash Summit in August 2015. So it’s very likely (0.85 probability) that Intel-Micron will produce 3D XPoint chips in the next 12 months.
Some systems (IBM FlashSystems, NetApp high-end, and HUS VM) could make use of raw chips or even a new level of storage connected to a memory bus. But all of them could easily take advantage of a 3D XPoint device that was an NVMe PCIe connected storage.
But to be useable for most vendor storage systems being GA’d over the next year, any new chip technology has to be available for use in 6 months at the latest.
4. How likely is it that Intel-Micron will produce servers with 3D XPoint in the next 6 months?
Listening in at Flash Summit this seems to be their preferred technological approach to market. And as most storage vendors use standard Intel Servers this would seem to be an easiest way to adopt it. If the chips are available, I deem it 0.65 probability that Intel will GA server hardware in the next 6 months with 3D XPoint technology.
Not sure any of the major or non-major vendors above could possible use server hardware introduced later than 6 months but Qumulo uses Agile development and releases GA code every 2 weeks, so they could take this on later than most.
But given the chip pricing, lack of significant advantage, and coding update requirements, I deem it 0.33 probability that vendors will adopt the technology even if it’s in a new server that they can use.
Summary
So there’s a 0.85 probability of chips available within 6 months for 3 potential major system that leaves us with 2.6 systems using 3D XPoint chip technology directly.
With a 0.65 probability of servers coming out in 6 months using 3D XPoint and a 0.45 of new storage systems adopting the technology for caching. That says there’s a 0.29 probability and with 18 new systems coming out. That says 5.2 systems could potentially adopt the server technology.
For a total of 7.8 systems out of a potential 22 new systems or a 0.35 probability.
That’s just the known GA non-major and storage startups what about the stealth(ier) startups without GA storage like Primary Data. There’s probably 2 or 3 non-GA storage startups. And if we assume the same 0.6 vendors will have GA hardware next year that is an additional 1.8 systems. More than likely these will depend on standard servers, so the 0.65 probability of Intel servers probability applies. So it’s likely we will see an additional 1.2 systems here or a total of 9.0 new systems that will adopt 3D XPoint tech in the next 12 months.
So it’s 9 systems out of 23.8 or ~0,38 probable. So my forecast is Yes at 0.38 probable.
Pricing is a key factor here. I assumed a single price but it’s more likely a range of possibilities and factoring in a pricing range would be more accurate but I don’t know how, yet.
~~~~
I could go on for another 1000 words and still be no closer to an estimate. Somebody please check my math.
Comments?
Photo Credit(s): (iTech Androidi) 3D XPoint – Intel’s new Storage chip is 1000 faster than flash memory




 Read an article today in Bitcoin magazine
Read an article today in Bitcoin magazine  Blockchain data is inherently widely available and distributed, in fact, blockchain data needs to be widely distributed in order to work properly.
Blockchain data is inherently widely available and distributed, in fact, blockchain data needs to be widely distributed in order to work properly. The ixo Protocol is a method to manage (SDG) Impact projects. It starts with 3 main participants: funding agencies, service agents and evaluation agents.
The ixo Protocol is a method to manage (SDG) Impact projects. It starts with 3 main participants: funding agencies, service agents and evaluation agents.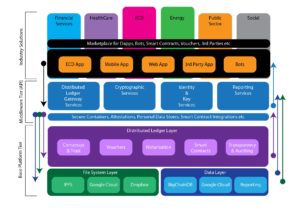 The
The 
 Read an article the other day from Recode (
Read an article the other day from Recode ( The course syllabus starts out referencing
The course syllabus starts out referencing  The next section of the course (week 4) talks about the natural ecology of BS.
The next section of the course (week 4) talks about the natural ecology of BS. The section on Fake News is very interesting. They reference an article in the
The section on Fake News is very interesting. They reference an article in the  In a FAST’16 article I recently read (
In a FAST’16 article I recently read (

 (from Flickr)")
{kind=link}