
At OCP summit researchers from NIST presented the winning paper and poster session, Supercomuters for AI based on Superconducting Optoelectronic Networks (SOENs) which discussed how one could use optical networking (waveguide, free space, optical fibre) with superconducting electronics (Single Photon Detectors, SPDs and Josephson Junctions, JJs) to construct an Neuromorphic simulation of biological neurons.
The cited paper is not available but the poster was (copied below) and it referred to an earlier paper, Optoelectronic Intelligence, which is available online if you want to learn more on the technology.

Some preliminaries before we hit the meat of the solution. Biological neurons are known to operate as spiking devices that only fire when sufficient input (ions, electronic charge) or a threshold of charge is present and once fired (or depleted), it takes another round of input ions of sufficient threshold of charge to make them fire again.

Biological neurons are connected to one another via dendrites which are long input connections and axons or output clusters via a synapse (air-liquid gap). Neurons are interconnected within micro-columns, columns, clusters and complexes which form the functional unit of the brain. Furtional units inter-connect (via axons – synapses – dendrite) to form brain subsystems such as the visual system, memory system, auditory system, etc..
DNNs vs the Human Brain
Current deep neural networks, DNNs, the underlying technology for all AI today is a digital approach to emulating brain electronic processing. DNNs uses layers of nodes, with each node connected to all the nodes in a layer above and all the nodes in layers below. For a specific DNN node to fire depends on its inputs multiplied by its weight and and added by its bias.
DNNs use a feed forward approach where inputs are fed into nodes at the bottom layer and proceed upward based on the weights and biases for each node in each layer resulting in an output at the top most layer (or bottom most layer depending on your preferred orientation).
Today’s DNN foundation models are built using trillions (10**12) of nodes (parameters) and consume city levels of power to train.
In comparison the human brain has approximately 10B (10**10) neurons and maybe 1000X that in connections between neurons. N.B. Neurons don’t connect to every neuron in a micro column.
So what’s apparent in the above is that the human brain requires significantly less neurons as compared to DNN nodes. And even with that significantly fewer neurons is capable of much more complex thought and reasoning. And the power consumption of the human brain is on the order of a few W, whereas foundation models which consume GW of power to train and KW to inference.
SOENs, a better solution
SOENs, superconducting optoelectronic networks, are a much closer approximation to human neurons and can be connected in such a fashion that within the scale of a couple of 2M**3 could support (with todays 45nm chip technology) 10B SOENs with 1000s of connections between them.
SOENs are a composite circuits representing single photon detectors (SPDs), Josephon Junctions (JJs) and light generating transistor circuits. Both the SPDs and JJs require cryogenic cooling to operate properly.


SOENs have biases and thresholds similar to both biological neurons and DNN nodes which are used to boost signals and as gates to limit firings.

When an SOEN fires it transmits a single photon of light to the reciever (SPD) of another SOEN. That photon travels within wafers in waveguides that are created in planes of the wafer. That photon could travel across to another wafer using optical connections. And that wafer could travel up or down using free space optics to wafers located above or below it.

There are other nueromorphic architectures out there but none that have the potential to scale to the human brain level of complexity with today’s technology.

And of course because SOENs are optoelectronics devices something on the scale of human brain (10B SOENs) would operate 1000s of times faster.

At the show the presenter mentioned that it would only take about $100M to fabricate the SOENs needed to simulate the equivalent of a human brain.
I think they should start a go-fund me project and get cracking… AGI is on the way.
And the real question is why stop there…

Picture Credits:
- Wikipedia article on Dendrite
- Picture of poster at OCP Summit
- From Optoelectronic Intelligence published paper
- From Optoelectronic Intelligence published paper
- From Optoelectronic Intelligence preprint
- From Optoelectronic Intelligence preprint

































 Read an article the other day about SpiNNaker, the University of Manchester’s neuromorphic supercomputer (see
Read an article the other day about SpiNNaker, the University of Manchester’s neuromorphic supercomputer (see 

 According to the home page and the Live Science article, SpiNNaker is intended to be used to model critical segments of the human brain such as the basal ganglia brain area for the EU HBP brain simulation program.
According to the home page and the Live Science article, SpiNNaker is intended to be used to model critical segments of the human brain such as the basal ganglia brain area for the EU HBP brain simulation program. MLP applications use back propagation and a training and inference phases, familiar to any deep learning application and uses a fixed neural network topology.
MLP applications use back propagation and a training and inference phases, familiar to any deep learning application and uses a fixed neural network topology.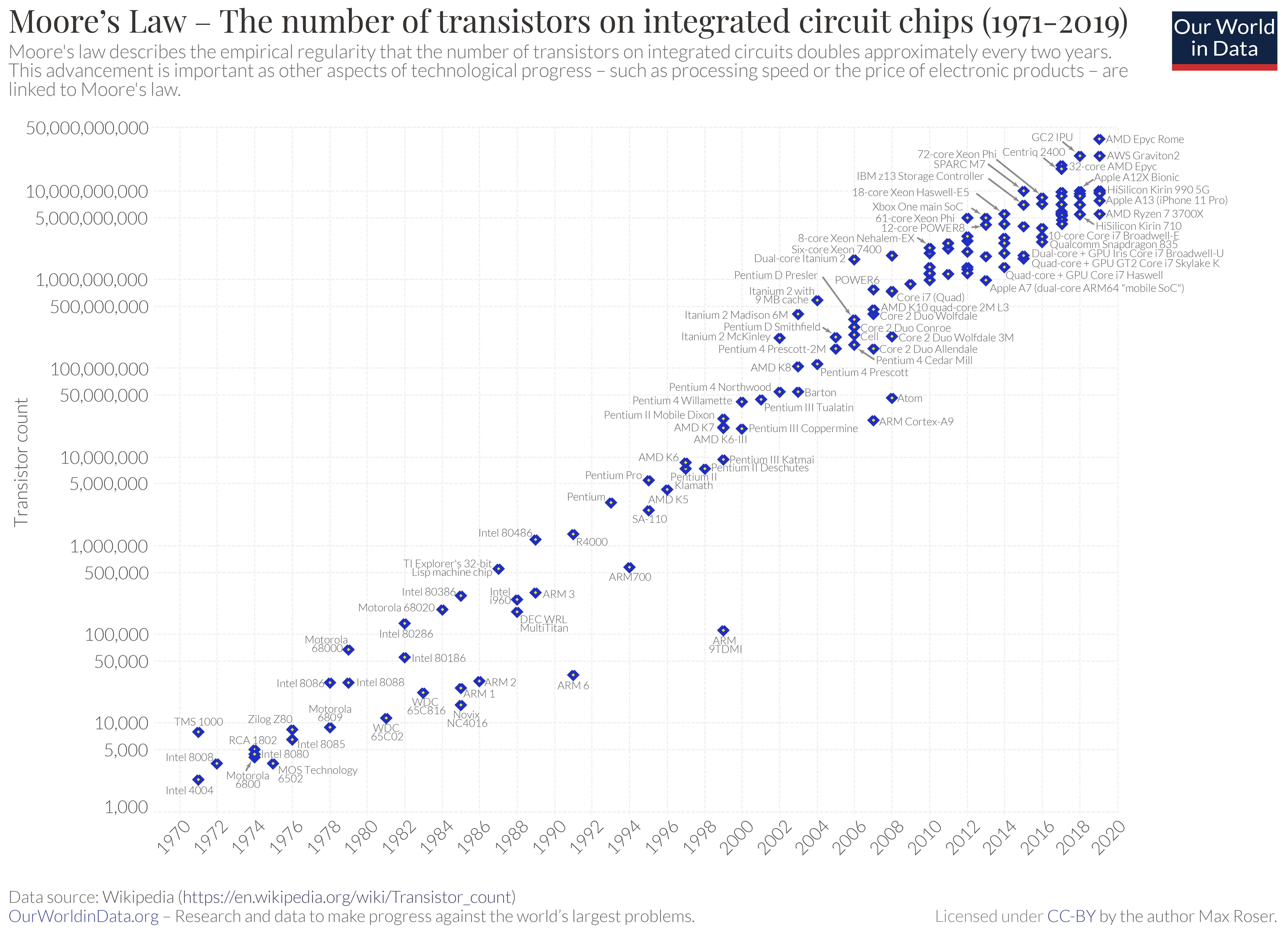{kind=link}